什么是决策树?
决策树有哪些优点?

决策树(Decision Tree)是一类经典的机器学习监督模型,被广泛用于分类和回归问题,也是一些机器学习集成模型,例如随机森林、XGBoost模型的基本结构单元。
顾名思义,决策树模型名称的由来就是因为其和一颗树一样,从底部的根向上生长,每个分支代表一个规则,每片叶子表示一个最终结果。
此外,决策树模型是树状结构模型的总称,根据分支的样本集合纯度度量指标的不同分为不同算法,其中具有标志性的是ID3、C4.5和CART。
决策树的结构如下所示:

从上图中,我们可以看到决策树的构成包括:
- 根节点:是树的起点,代表整个数据集;
- 决策节点/内部节点:图1中的灰篮色框,每个灰蓝色框代表一条决策规则,根据这个规则将数据分成不同部分;(例如根据规则“月薪是否达到50000”将数据分成“达到”和“没有达到”两部分。)
- 叶节点:图1中的绿色框,代表决策结果;
那么思考一个问题:图1中3条决策规则的顺序对于决策树来说要怎么确定呢?
这就要从决策树背后的数学原理来理解了。
决策树背后的数学原理
</font
要记住:决策树是通过能够度量样本子集同质程度的指标来确定决策规则的顺序的,根据度量指标的不同对应不同决策树算法。
决策树每个决策节点的划分都会产生两个或多个数据子集,我们必然是希望同一个子集中的数据“纯度”或者说同质度越高越好,不同子集间的区分度越高越好。
- 例如对于猫和狗的数据分类,我们用“叫声是否为汪汪汪”这一决策规则就能把两者完全区分开来,这样的决策规则我们希望离根节点越近越好。
度量样本集“纯度”的指标主要包括基于信息熵的信息增益和信息增益率,以及基尼指数,基于这三种“纯度”指标的决策树算法分别为ID3、C4.5和CART。
- 信息增益(information gain)
ID3算法是根据基于信息熵(information entropy)的信息增益来度量数据子集的“纯度”的。
假设数据集的结局变量_Y_有_J_个类别
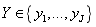
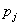

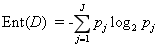
Ent(D)的值越小代表该节点中D的纯度越高。
==例如D中只有一个类别的数据,那么


假设该节点的决策规则r有K个可能取值,那么数据集将被划分为子集
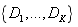
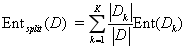
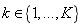
式中
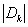
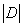
既然有了数据划分前后的信息熵,我们就能够得到利用该决策规则r对数据集D划分前后的信息熵变化,这一差值称为“信息增益”(information gain):
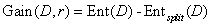
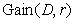
- ID3算法就是根据信息增益指标来确定具体决策规则和规则顺序的,越大的决策规则将出现在越接近根结点的位置。


√但思考这样一个问题:如果把“数据编号“这一变量作为决策规则,那么将产生和数据条数相同数量的数据子集,每个子集都只有一条数据,也就是说用这一变量就能实现最大信息增益,Gain(D,r)=Ent(D)。但**显然这样的决策树不具备泛化能力,对外部数据无法有效预测。**
从这个问题也能看出信息增益指标存在的问题了。
事实上,信息增益指标偏好于取值数目较多的规则,为了纠正这种偏好,之后有学者在信息增益指标基础上提出了“信息增益率”。
- 信息增益率(information gain ratio)
C4.5算法就是根据信息增益率来度量数据子集的“纯度”的。信息增益率通过将和规则的取值数目相关的项作为分母来惩罚取值数目较多的规则,计算公式为:
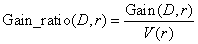
式中
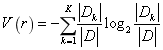
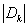
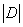
- 基尼指数(gini index)
CART算法是根据 “基尼指数”来度量数据子集的“纯度”的。采用和信息熵计算相同的符号表示,对于每个决策节点,数据集的_D_基尼指数为:
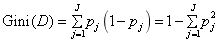
可以看到,_Gini(D)_的直观理解是从该节点上随机选取两个样本,两者类别不一致的概率。因此G_ini(D)_越小就代表_D_的纯度越高。
那么利用决策规则_r_对_D_划分后的基尼指数则为_K_个数据子集的基尼指数的加权和:
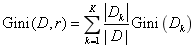
对D划分后Gini(_D,r)_越小的决策规则r就越靠近根节点的位置。
决策树具体的训练过程
干讲数学原理比较抽象,我们用一个简单例子来讲解决策树的训练过程。
三大决策树算法的背后思想都是一致的,只是用了不同的数据纯度衡量指标,理解了其中一个算法也就明白了决策树是怎么回事。
相比ID3和C4.5只能进行分类任务,CART还可以进行回归任务,是目前最主流的决策树算法,我们用CART决策树的构建作为示例。
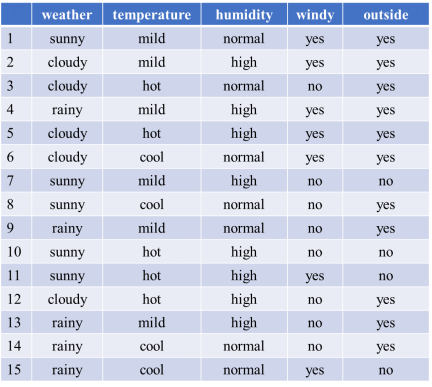
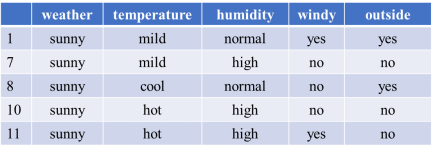
我们看下表数据集,数据集包括了15天的环境(weather、temperature、humidity、windy)和出去玩(outside)的情况,我们构建CART决策树模型来根据环境因素预测是否出去玩。
- 首先确定第一层的决策节点
为了确定第一层决策节点,需要计算所有环境变量各属性的基尼指数。
首先看weather(天气)变量,为方便后续计算,我们先把该变量3个属性对应的outside(出去玩)情况列出来。
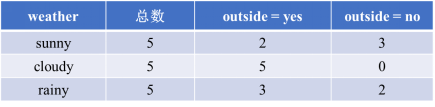
由于CART是二叉树结构,当变量有多个属性时需要合并成2个,因此weather变量的属性共有3种组合。
第一种组合: sunny、cloudy和rainy
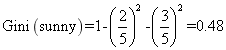

组合一的基尼指数为:
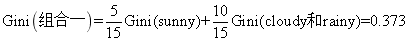
第二种组合: cloudy、sunny和rainy
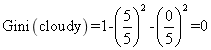
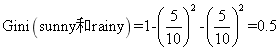
组合二的基尼指数为:
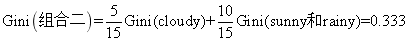
第三种组合: rainy、sunny和cloudy
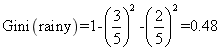
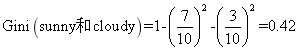
组合三的基尼指数为:
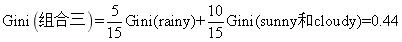
按照这种方式计算所有环境变量各属性的基尼指数,得到:
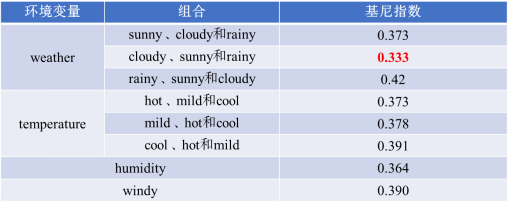
weather变量第2个属性组合的基尼指数最小,故以其作为第一层的决策节点,经过该节点后数据集_D_被分成三个子集D1、D2和D3,如下图。

D1的outside已经全都是yes了,即_Gini(_D1)=0,不再对D1建立下一层决策节点。但D2和D3中outside并不都是同一类别,可以进一步划分。
- 之后以相同方式确定后面层的决策节点
先看数据集D2,
和_D_中确定决策节点一样,针对D2计算temperature、humidity和windy变量各属性的基尼指数为:
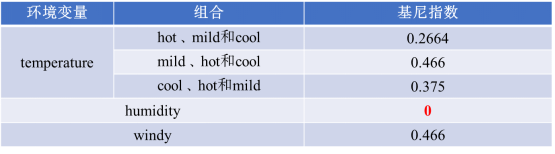
humidity的基尼指数最小,故以其作为D2的决策节点。经humidity划分后的数据子集的outside都为同一类,停止进一步划分。
对于数据集D3,
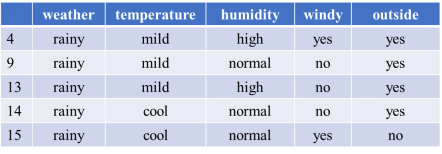
计算temperature、humidity和windy变量各属性的基尼指数为:

temperature和windy的基尼指数一样小,任选其中一个作为D3的决策节点。
这里选择temperature划分D3,划分后属性为mild的数据的outside全部为yes,属性为cool的数据的outside一个为yes另一个为no。
然而由于无法通过humidity变量进一步划分,只能任选yes或no之一作为判定结果,我们这里选择no。
CART决策树模型最终构建如下
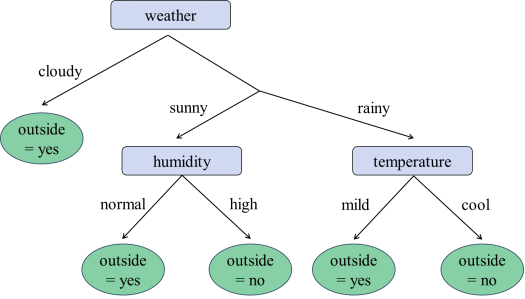
有了这一模型后,我们就可以利用天气预报数据预判明天出不出去玩了。
此外值得一提的是,在训练决策树过程中,为了尽可能将更多样本正确分类,可能会将样本数已经很小的数据子集进一步细分。
这会使得决策树分支数过多,以致于将部分数据的一些特性当作所有数据的普遍属性,导致模型对外部数据的预测效果不好——这种现象称为“过拟合”。
为了降低决策树的过拟合风险,可以主动去掉一些分支,该技术称为剪枝(pruning)。

剪枝和日常树木修剪是一个道理,包括两种策略:
- 预剪枝: 在决策树生成前做某些限制,例如限制最大分支数、限制叶节点最小样本数,不让树生成太多分支;
- 后剪枝: 在决策树完全生成后,根据交叉验证等方式剪掉对泛化性没有帮助的分支。
决策树的优缺点
优点
- 模型结构简单直观,预测结果易理解: 决策树的结构用一张图就能表示出来并且决策规则明确,很容易给不了解决策树的人解释预测结果是怎么得到的;
- 不需要太多数据预处理: 决策树能容忍数据中存在缺失值,并且无需像应用线性回归模型时那样对数据进行归一化处理;
- 无需人为指定模型具体形式: 作为机器学习方法中的一种,决策树无需假设数据分布,并且具有机器学习方法共有的能够自动捕捉因变量与自变量之间复杂的非线性关系的能力。
缺点
- 容易过拟合: 例如在特征数较多时,如果不进行适当的剪枝,决策树可能会过度生长,对训练数据过度拟合,导致泛化能力差;
- 模型结构不稳定: 决策树对数据集中的异常值和噪声比较敏感,模型结构可能会因数据集小的变动而发生很大变化;
- 偏好于取值数目多的特征: ID3和CART算法都容易将取值数目多的特征放到靠近根节点的位置,数据划分可能会过度依赖这些变量。
设置LaTeX渲染永远是第一件事情
import matplotlib.pyplot as plt
# 启用LaTeX文本渲染
plt.rcParams.update({
"text.usetex": True,
"font.family": "serif",
"font.serif": ["Computer Modern Roman"],
})